I’m going to take a quick break from our pharmaceutical banter to share with you the history of grocery shopping. As strange as it may seem, the transformation of the food shopping process in the last century relates to how we’ve changed clinical trial research in the last decade.
The first self-service supermarket as we know it was conceived by Vincent Astor in 1915. He named his store Astor Market and opened shop in New York City. Before supermarkets like Astor Market existed, we consumers needed to visit several specialty vendors. It was a one-at-time system where a customer would walk up to a counter and ordered items, just like a deli. But instead of having one place to get all your items, you would go to the greengrocer, the butcher, bakery, dry goods store, and so on. With today’s time-is-precious attitude, could you imagine having to make 5 or 6 stops just to collect ingredients for dinner?
Supermarkets provided value to consumers by simplifying the shopping process. The offerings of six food stores are now consolidated into a single location. A benefit of this simplification to think about as I make the analogy for clinical trials, is that with a simplified shopping process, consumers are likely to use more ingredients, and work on more extensive recipes.
Just like the transformation in food shopping process that took place over the 20th century, as more clinical trial data is being made public through online clinical trial registries, the sources from which we obtain information about clinical development are consolidating. Instead of scouring multiple medical journals or the pink sheets, we use the self-service centers of study data known as online registries. But the current options aren’t yet a one-stop-shop for clinical development info – we often visit multiple registries to collect the data we need. Here’s a list of registries clinical trial analysts use:
In addition, most countries have their own registry, such as Japan’s UMIN.
So, what are we to do about having all these data sources? Can’t we just combine them all somehow? Not quite. I’d like to explain that, but first I’d also like to discuss why ClinicalTrials.gov (CT.g) is the best free resource for the current time, what it’s missing, and what we should gain by collectively developing it into the global supermarket of clinical trial data until the next best solution comes around.
Why CT.g Is the Best Global Source
Simply put, at this time CT.g is the most comprehensive clinical trial data source. Even though it’s managed by the NIH, which is a United States government specific organization, we estimate that over 80% of global trial data is contained within CT.g for two reasons.
1. Sponsors need an NCT number to later apply for a new drug application through the FDA.
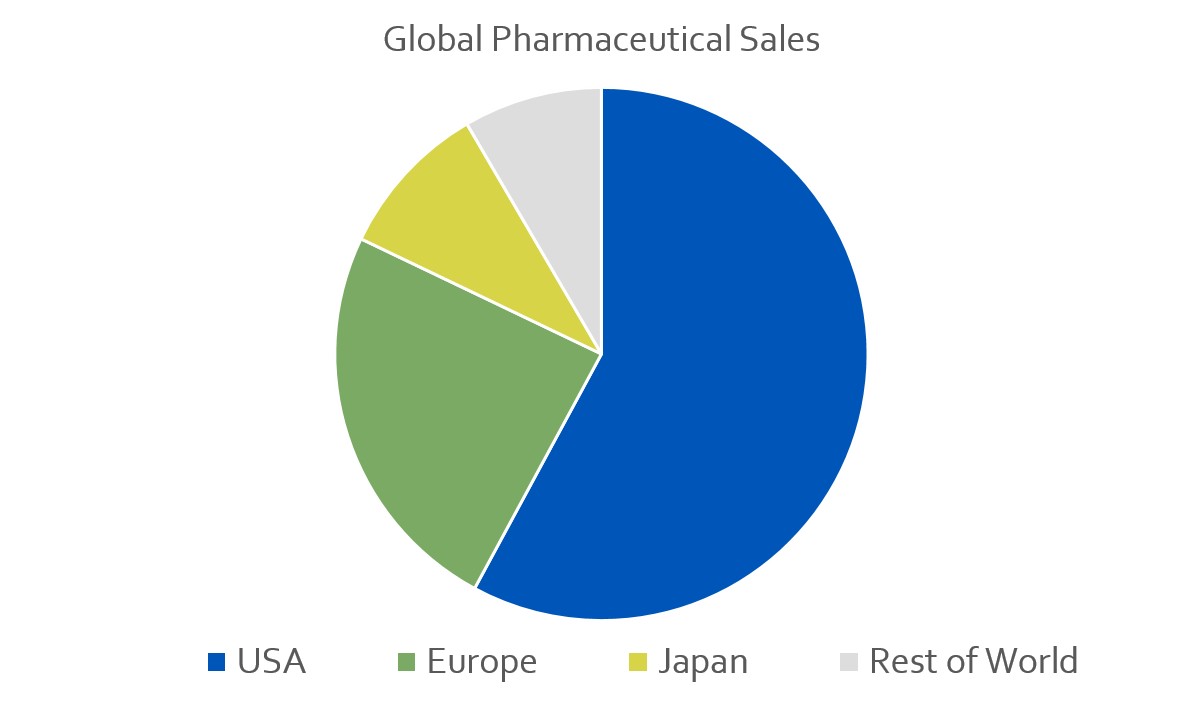
The US is the single biggest market for pharmaceutical products and devices in the world. From 2009 to 2013, the US accounted for 55% of global sales for new medicines. For comparison Europe accounted for 23%, Japan was 9%, and the rest of the world was at 8%. Therefore, if someone’s going to make the giant fiscal and time investment of developing a new drug, they’re going to need to hit the US market to sell to more than half of the addressable market. To do this, they’ll need an NCT number by registering their trials on CT.g.
2. Sponsors need an NCT number to publish the results of the trial in medical publications, as enforced by the International Committee of Medical Journal Editors.
Therefore, investigators who coordinate trials for non-commercial purposes are still incentivized to register trials on CT.g to share their work with the medical community.
Comparing Databases
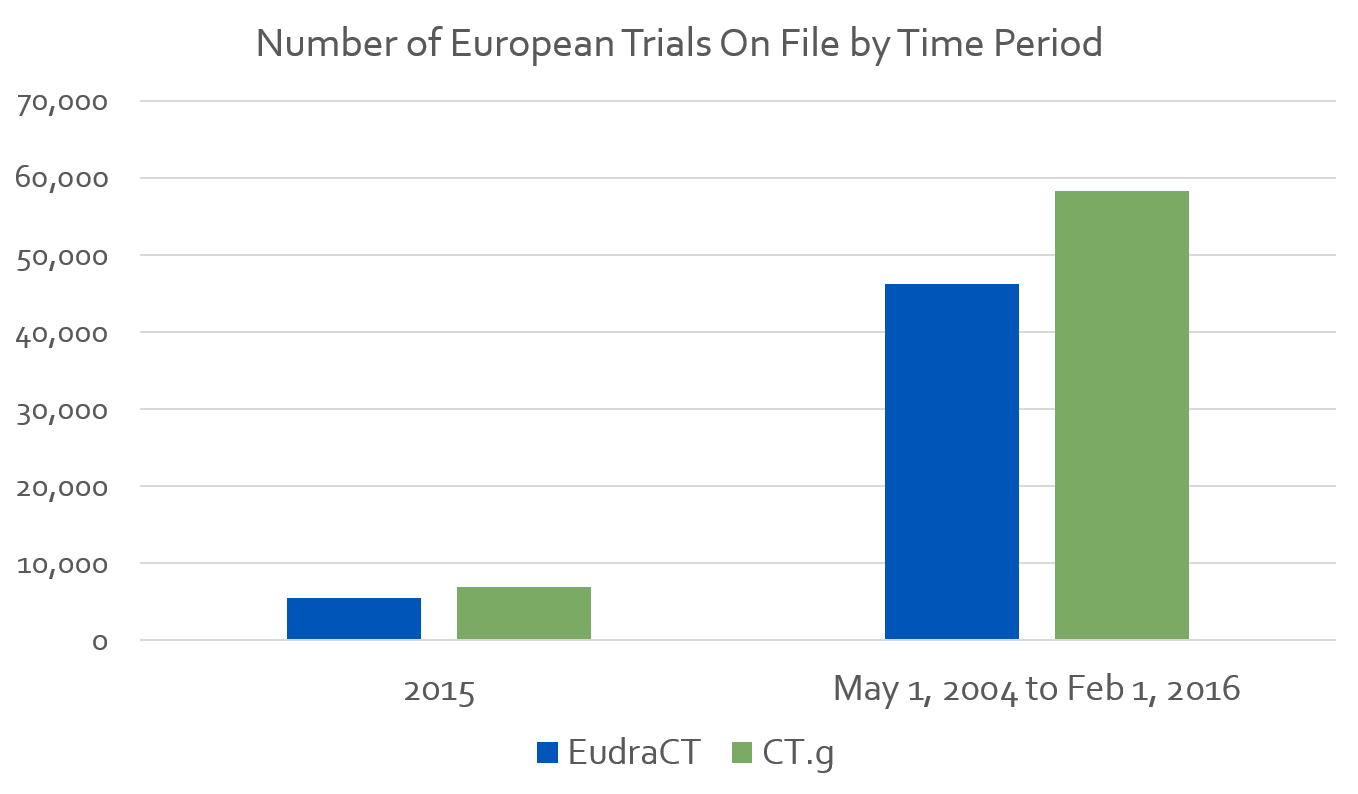
To show the overlap the CT.g database has with countries outside the US, let’s compare the number of studies in EudraCT to the number of European studies in CT.g.
Per the European Medicines Agency, EudraCT registered 5,526 trials in 2015. For the same year, CT.g has data on 6,975 trials taking place in Europe.
From EudraCT’s existence on May 1st 2004 to February 1st 2016 the registry has data from 46,206 trials on file. The CT.g database, for the same period, contains 58,302 trials.
This is not an apples to apples comparison. CT.g defines Europe as the entire continent, while EudraCT focuses on the 28 EU member states. Still it appears CT.g may be a more exhaustive source of trial data for the European region than EudraCT.
What CT.g Is Missing
An organization that’s developing products intended to never be sold in the US or mentioned in ICMJE approved medical publications isn’t incentivized to register on CT.g. These trials are few and far between, but they do exist. Examples may include:
- Trials organized by smaller foreign academic sponsors,
- Trials executed outside of US government approved guidelines,
- Products developed without Western consumers in mind
CT.g is the most exhaustive resource out there today, but it’s not completely exhaustive. It’s designed and serves its purpose for the US market. The fact that it has been widely adopted by foreign sponsors is just a major benefit.
What would be best for the worldwide medical community is a global repository – one place of storage for all clinical trial data.
The Benefit of a Global Repository
With the advent of the supermarket, the food shopping process became a lot quicker and easier for consumers. Because we save time from needing to go from specialized vendor to vendor, we are more likely to gather a thorough list of ingredients for our meals. In the same way, a global repository of clinical trial data will save time for researchers. Less effort to do more exhaustive searching produces more thorough research.
A global repository will also inform future clinical development with larger volumes of data. With more data, more accurate conclusions can be made, duplication of efforts can be reduced, and the advancement of healthcare will accelerate. The result can be better care for patients, and faster development of life changing cures and vaccines.
There will still be a need for region specific databases. Patients will need registries that make it easy to find local trial sites, while regional medical conditions also exist. However, local registries could be a feature of a larger worldwide repository.
Why We Can’t Combine All the Data Sources
At the beginning of this post I listed several registries researchers and analysts use to collect information. Why couldn’t we just combine these data sources? Because this would lead to massive duplication errors.
There isn’t a good way to identify at scale which studies, drugs, and devices are overlapping in datasets. For example, a sponsor may one title for a study on ClinicalTrials.gov, and a different title for the same study on EudraCT. Even if all titles were the same, there isn't a sure way to eliminate duplicates when combining CT.g and EudraCT datasets. Of course, there are ways to minimize duplication errors, but there is no silver bullet.
There are benefits of combining the two even if there are errors, but it won’t always lead to drawing more accurate conclusions from the data. In other words, while more data is better than less data, working with clean data is better than working with dirty data.
In the meantime, the more widely CT.g is adopted across the world, the greater its benefit to the global community. Yes, there are limitations as it’s a US government funded and curated registry. But it’s a starting point. And from this starting point a global repository could be designed. If it’s designed using a key field from CT.g such as NCT number, then duplication errors won’t be an issue.
Until that fantastical repository is built, BrackenData will continue to use CT.g as a primary source for our dashboards (after we download and clean the data for errors). We do collect data from several other sources, but we are cautious about which datapoints we combine. We prefer to provide clear insight into 80% of the world’s clinical trial data, than a speculative view of 95%. Because of this, our customers don’t need to go shopping for information at a number of different data sources and vendors. They can extract information from our clinical trial data quickly and without speculation.

-1.png?width=352&name=BM_The%20Leaflet%20Newsletter%20Images%20(2)-1.png)
